1A. Make sure the document has encoding UTF-8. Choose Encoding->UTF-8.
2. Copy all the text in the below Cached Result window, starting with line 'List of Unicode Control Characters'.
This list begins with the first letter character in ASCII, which in Unicode format is expressed as \u0000 (hex value 00) and is referred to as null character.
A quick note about common control characters;
- CR LF - 2 characters (carriage return & line feed) combined used to represent a new line usually in Windows operating system (see Settings → Preferences → New Document)
- LF - is a line feed character represents a new line usually in UNIX/Linux/ operating systems (see Preferences → New Document)
- CR is a carriage return character represents a new line usually in Apple operating systems (see Preferences → New Document)
- → - is a Horizontal Tabulation (aka "tab", hex 09, or \t) character that right shifts text. In Notepad++, tabs can be replaced by spaces depending on settings. See see Settings → Preferences → Language → Replace by Space
Notepad++ indicated control characters with white lettering on a black background such as SOH, STX, ETX, EOT, BS, etc, which you can easily match to tables below.
For example, the character named 'bell' ('\a') will be displayed as BEL as indicated by the Acronym column in the table below.
5. Now remove control characters using Find and Replace
- Ctrl+H
- Find what: [\x00-\x09\x0B-\x0C\x80-\xFF\x99\x92x99\x92]
- Replace with:
LEAVE EMPTY - CHECK Wrap around
- CHECK Regular expression
- Replace all
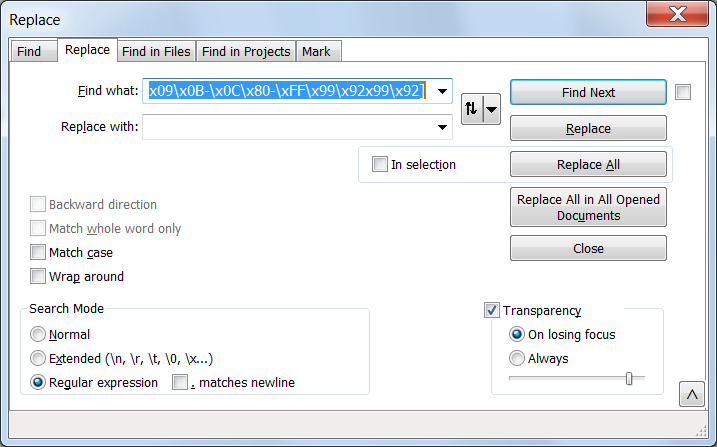
Tab Character Replacement in Notepad++
If you deselect checkbox, then Tab (\u0009) character is displayed as → (right arrow).


| Hex | Acronym | Name | C | Description |
|---|---|---|---|---|
| 00 | NUL | Null |
\0 |
Originally used to allow gaps to be left on paper tape for edits. Later used for padding after a code that might take a terminal some time to process (e.g. a carriage return or line feed on a printing terminal). Now often used as a string terminator, especially in the programming language C. |
| 01 | SOH | Start of Heading | First character of a message header. In Hadoop, it is often used as a field separator. | |
| 02 | STX | Start of Text | First character of message text, and may be used to terminate the message heading. | |
| 03 | ETX | End of Text | Often used as a "break" character (Ctrl-C) to interrupt or terminate a program or process. | |
| 04 | EOT | End of Transmission | Often used on Unix to indicate end-of-file on a terminal. | |
| 05 | ENQ | Enquiry | Signal intended to trigger a response at the receiving end, to see if it is still present. | |
| 06 | ACK | Acknowledge | Response to an ENQ, or an indication of successful receipt of a message. | |
| 07 | BEL | Bell, Alert |
\a |
Originally used to sound a bell on the terminal. Later used for a beep on systems that didn't have a physical bell. May also quickly turn on and off inverse video (a visual bell). |
| 08 | BS | Backspace |
\b |
Move the cursor one position leftwards. On input, this may delete the
character to the left of the cursor. On output, where in early computer
technology a character once printed could not be erased, the backspace
was sometimes used to generate accented characters in ASCII. For
example, à could
be produced using the three character sequence a
BS ` (or, using the characters’ hex values, 0x61
0x08 0x60). This usage is now deprecated and generally not
supported. To provide disambiguation between the two potential uses of
backspace, the cancel
character control code was made part of the standard C1 control set. |
| 09 | HT | Character Tabulation, Horizontal Tabulation |
\t |
Position to the next character tab stop. |
| 0A | LF | Line Feed |
\n |
On typewriters, printers, and some terminal emulators, moves the cursor down one row without affecting its column position. On Unix, used to mark end-of-line. In DOS, Windows, and various network standards, LF is used following CR as part of the end-of-line mark. |
| 0B | VT | Line Tabulation, Vertical Tabulation |
\v |
Position the form at the next line tab stop. |
| 0C | FF | Form Feed |
\f |
On printers, load the next page. Treated as whitespace in many programming languages, and may be used to separate logical divisions in code. In some terminal emulators, it clears the screen. It still appears in some common plain text files as a page break character, such as the RFCs published by IETF. |
| 0D | CR | Carriage Return |
\r |
Originally used to move the cursor to column zero while staying on the same line. On classic Mac OS (pre-Mac OS X), as well as in earlier systems such as the Apple II and Commodore 64, used to mark end-of-line. In DOS, Windows, and various network standards, it is used preceding LF as part of the end-of-line mark. The Enter or Return key on a keyboard will send this character, but it may be converted to a different end-of-line sequence by a terminal program. |
| 0E | SO | Shift Out | Switch to an alternative character set. | |
| 0F | SI | Shift In | Return to regular character set after Shift Out. | |
| 10 | DLE | Data Link Escape | Cause the following octets to be interpreted as raw data, not as control
codes or graphic characters. Returning to normal usage would be
implementation dependent. |
|
| 11 | DC1 | Device Control One (XON) | These four control codes are reserved for device control, with the interpretation dependent upon the device to which they were connected. DC1 and DC2 were intended primarily to indicate activating a device while DC3 and DC4 were intended primarily to indicate pausing or turning off a device. DC1 and DC3 (known also as XON and XOFF respectively in this usage) originated as the "start and stop remote paper-tape-reader" functions in ASCII Telex networks. This teleprinter usage became the de facto standard for software flow control.[6] | |
| 12 | DC2 | Device Control Two | ||
| 13 | DC3 | Device Control Three (XOFF) | ||
| 14 | DC4 | Device Control Four | ||
| 15 | NAK | Negative Acknowledge | Sent by a station as a negative response to the station with which the connection has been set up. In binary synchronous communication protocol, the NAK is used to indicate that an error was detected in the previously received block and that the receiver is ready to accept retransmission of that block. In multipoint systems, the NAK is used as the not-ready reply to a poll. | |
| 16 | SYN | Synchronous Idle | Used in synchronous transmission systems to provide a signal from which synchronous correction may be achieved between data terminal equipment, particularly when no other character is being transmitted. | |
| 17 | ETB | End of Transmission Block | Indicates the end of a transmission block of data when data are divided into such blocks for transmission purposes. | |
| 18 | CAN | Cancel | Indicates that the data preceding it are in error or are to be disregarded. | |
| 19 | EM | End of medium | Intended as means of indicating on paper or magnetic tapes that the end of the usable portion of the tape had been reached. | |
| 1A | SUB | Substitute | Originally intended for use as a transmission control character to indicate that garbled or invalid characters had been received. It has often been put to use for other purposes when the in-band signaling of errors it provides is unneeded, especially where robust methods of error detection and correction are used, or where errors are expected to be rare enough to make using the character for other purposes advisable. In DOS, Windows and other CP/M derivatives, it is used to indicate the end of file, both when typing on the terminal, and sometimes in text files stored on disk. | |
| 1B | ESC | Escape | \e[b] | The Esc
key on the keyboard will cause this character to be sent on most
systems. It can be used in software user interfaces to exit from a
screen, menu, or mode, or in device-control protocols (e.g., printers
and terminals) to signal that what follows is a special command sequence
rather than normal text. In systems based on ISO/IEC
2022, even if another set of C0 control codes are used, this octet
is required to always represent the escape character. |
| 1C | FS | File Separator | Can be used as delimiters to mark fields of data structures. If used for hierarchical levels, US is the lowest level (dividing plain-text data items), while RS, GS, and FS are of increasing level to divide groups made up of items of the level beneath it. | |
| 1D | GS | Group Separator | ||
| 1E | RS | Record Separator | ||
| 1F | US | Unit Separator |
| Hex | Acro | Name | Description |
|---|---|---|---|
| 7F | DEL | Delete Character | In computing, the delete character (sometimes also called rubout) is the last character in the ASCII repertoire, with the code 127 (decimal). Not a graphic character but a control character, it is denoted as ^? in caret notation and has a graphic representation of ␡ in Unicode (as all ASCII control characters have graphic representations).A key marked Backspace ← that sends the Backspace character is by far the most common on modern terminals and emulators. Due to the "backspace" key sending Delete on many terminals, keys marked "Delete" typically do not send the character, instead sending an Escape sequence similar to the arrow keys.[6] |
| 80 | PAD | Padding Character | Not part of ISO/IEC 6429 (ECMA-48). In early drafts of ISO 10646, was used as part of a proposed mechanism to encode non-ASCII characters. This use was removed in later drafts.[2][7] Is nonetheless used by the internal-use two-byte fixed-length form of the ISO-2022-based Extended Unix Code (EUC) for left-padding single byte characters in code sets 1 and 3, whereas NUL serves the same function for code sets 0 and 2. This is not done in the usual "packed" EUC format.[8] |
| 81 | HOP | High Octet Preset | Not part of ISO/IEC 6429 (ECMA-48). In early drafts of ISO 10646, was intended as a means of introducing a sequence of ISO 2022 compliant multiple byte characters with the same first byte without repeating said first byte, thus reducing length; this behaviour was never part of a standard or published implementation. Its name was nonetheless retained as a RFC 1345 standard code-point name.[2][7] |
| 82 | BPH | Break Permitted Here | Follows a graphic character where a line break is permitted. Roughly equivalent to a soft hyphen except that the means for indicating a line break is not necessarily a hyphen. Not part of the first edition of ISO/IEC 6429.[9] See also zero-width space. |
| 83 | NBH | No Break Here | Follows the graphic character that is not to be broken. Not part of the first edition of ISO/IEC 6429.[9] See also word joiner. |
| 84 | IND | Index | Move the active position one line down, to eliminate ambiguity about the meaning of LF. Deprecated in 1988 and withdrawn in 1992 from ISO/IEC 6429 (1986 and 1991 respectively for ECMA-48). |
| 85 | NEL | Next Line | Equivalent to CR+LF. Used to mark end-of-line on some IBM mainframes. |
| 86 | SSA | Start of Selected Area | Used by block-oriented terminals. |
| 87 | ESA | End of Selected Area | |
| 88 | HTS | Character Tabulation Set Horizontal Tabulation Set |
Causes a character tabulation stop to be set at the active position. |
| 89 | HTJ | Character Tabulation With Justification Horizontal Tabulation With Justification |
Similar to Character Tabulation, except that instead of spaces or lines being placed after the preceding characters until the next tab stop is reached, the spaces or lines are placed preceding the active field so that preceding graphic character is placed just before the next tab stop. |
| 8A | VTS | Line Tabulation Set Vertical Tabulation Set |
Causes a line tabulation stop to be set at the active position. |
| 8B | PLD | Partial Line Forward Partial Line Down |
Used to produce subscripts and superscripts in ISO/IEC
6429, e.g., in a printer. Subscripts use PLD text PLU while
superscripts use PLU text PLD. |
| 8C | PLU | Partial Line Backward Partial Line Up |
|
| 8D | RI | Reverse Line Feed Reverse Index |
|
| 8E | SS2 | Single-Shift 2 | Next character invokes a graphic character from the G2 or G3 graphic sets respectively. In systems that conform to ISO/IEC 4873 (ECMA-43), even if a C1 set other than the default is used, these two octets may only be used for this purpose. |
| 8F | SS3 | Single-Shift 3 | |
| 90 | DCS | Device Control String | Followed by a string of printable characters (0x20 through 0x7E) and format effectors (0x08 through 0x0D), terminated by ST (0x9C). |
| 91 | PU1 | Private Use 1 | Reserved for a function without standardized meaning for private use as required, subject to the prior agreement of the sender and the recipient of the data. |
| 92 | PU2 | Private Use 2 | |
| 93 | STS | Set Transmit State | |
| 94 | CCH | Cancel character | Destructive backspace, intended to eliminate ambiguity about meaning of BS. |
| 95 | MW | Message Waiting | |
| 96 | SPA | Start of Protected Area | Used by block-oriented terminals. |
| 97 | EPA | End of Protected Area | |
| 98 | SOS | Start of String | Followed by a control string terminated by ST (0x9C) that may contain any character except SOS or ST. Not part of the first edition of ISO/IEC 6429.[9] |
| 99 | SGCI | Single Graphic Character Introducer | Not part of ISO/IEC 6429. In early drafts of ISO 10646, was used to encode a single multiple-byte character without switching out of a HOP mode. In later drafts, this facility was removed, the name was nonetheless retained as a RFC 1345 standard code-point name.[2][7] |
| 9A | SCI | Single Character Introducer | To be followed by a single printable character (0x20 through 0x7E) or format effector (0x08 through 0x0D). The intent was to provide a means by which a control function or a graphic character that would be available regardless of which graphic or control sets were in use could be defined. Definitions of what the following byte would invoke was never implemented in an international standard. Not part of the first edition of ISO/IEC 6429.[9] |
| 9B | CSI | Control Sequence Introducer | Used to introduce control sequences that take parameters. |
| 9C | ST | String Terminator | |
| 9D | OSC | Operating System Command | Followed by a string of printable characters (0x20 through 0x7E) and format effectors (0x08 through 0x0D), terminated by ST (0x9C). These three control codes were intended for use to allow in-band signaling of protocol information, but are rarely used for that purpose. |
| 9E | PM | Privacy Message | |
| 9F | APC | Application Program Command |
2.1 Explicit Directional Embeddings
The following characters signal that a piece of text is to be treated as embedded. For example, an English quotation in the middle of an Arabic sentence could be marked as being embedded left-to-right text. If there were a Hebrew phrase in the middle of the English quotation, that phrase could be marked as being embedded right-to-left text. Embeddings can be nested one inside another, and in isolates and overrides.
| Abbr. | Code Point | Name | Description |
|---|---|---|---|
| LRE | U+202A | LEFT-TO-RIGHT EMBEDDING | Treat the following text as embedded left-to-right. |
| RLE | U+202B | RIGHT-TO-LEFT EMBEDDING | Treat the following text as embedded right-to-left. |
The effect of right-left line direction, for example, can be accomplished by embedding the text with RLE...PDF. (PDF will be described in Section 2.3, Terminating Explicit Directional Embeddings and Overrides.)
2.2 Explicit Directional Overrides
The following characters allow the bidirectional character types to be overridden when required for special cases, such as for part numbers. They are to be avoided wherever possible, because of security concerns. For more information, see [UTR36]. Directional overrides can be nested one inside another, and in embeddings and isolates.
| Abbr. | Code Point | Name | Description |
|---|---|---|---|
| LRO | U+202D | LEFT-TO-RIGHT OVERRIDE | Force following characters to be treated as strong left-to-right characters. |
| RLO | U+202E | RIGHT-TO-LEFT OVERRIDE | Force following characters to be treated as strong right-to-left characters. |
The precise meaning of these characters will be made clear in the discussion of the algorithm. The right-to-left override, for example, can be used to force a part number made of mixed English, digits and Hebrew letters to be written from right to left.
2.3 Terminating Explicit Directional Embeddings and Overrides
The following character terminates the scope of the last LRE, RLE, LRO, or RLO whose scope has not yet been terminated.
| Abbr. | Code Point | Name | Description |
|---|---|---|---|
| U+202C | POP DIRECTIONAL FORMATTING | End the scope of the last LRE, RLE, RLO, or LRO. |
The precise meaning of this character will be made clear in the discussion of the algorithm.
2.4 Explicit Directional Isolates
The following characters signal that a piece of text is to be treated as directionally isolated from its surroundings. They are very similar to the explicit embedding formatting characters. However, while an embedding roughly has the effect of a strong character on the ordering of the surrounding text, an isolate has the effect of a neutral like U+FFFC OBJECT REPLACEMENT CHARACTER, and is assigned the corresponding display position in the surrounding text. Furthermore, the text inside the isolate has no effect on the ordering of the text outside it, and vice versa.
In addition to allowing the embedding of strongly directional text without unduly affecting the bidirectional order of its surroundings, one of the isolate formatting characters also offers an extra feature: embedding text while inferring its direction heuristically from its constituent characters.
Isolates can be nested one inside another, and in embeddings and overrides.
| Abbr. | Code Point | Name | Description |
|---|---|---|---|
| LRI | U+2066 | LEFT‑TO‑RIGHT ISOLATE | Treat the following text as isolated and left-to-right. |
| RLI | U+2067 | RIGHT‑TO‑LEFT ISOLATE | Treat the following text as isolated and right-to-left. |
| FSI | U+2068 | FIRST STRONG ISOLATE | Treat the following text as isolated and in the direction of its first strong directional character that is not inside a nested isolate. |
The precise meaning of these characters will be made clear in the discussion of the algorithm.
2.5 Terminating Explicit Directional Isolates
The following character terminates the scope of the last LRI, RLI, or FSI whose scope has not yet been terminated, as well as the scopes of any subsequent LREs, RLEs, LROs, or RLOs whose scopes have not yet been terminated.
| Abbr. | Code Point | Name | Description |
|---|---|---|---|
| PDI | U+2069 | POP DIRECTIONAL ISOLATE | End the scope of the last LRI, RLI, or FSI. |
The precise meaning of this character will be made clear in the discussion of the algorithm.
2.6 Implicit Directional Marks
These characters are very light-weight formatting. They act exactly like right-to-left or left-to-right characters, except that they do not display or have any other semantic effect. Their use is more convenient than using explicit embeddings or overrides because their scope is much more local.
| Abbr. | Code Point | Name | Description |
|---|---|---|---|
| LRM | U+200E | LEFT-TO-RIGHT MARK | Left-to-right zero-width character |
| RLM | U+200F | RIGHT-TO-LEFT MARK | Right-to-left zero-width non-Arabic character |
| ALM | U+061C | ARABIC LETTER MARK | Right-to-left zero-width Arabic character |
There is no special mention of the implicit directional marks in the following algorithm. That is because their effect on bidirectional ordering is exactly the same as a corresponding strong directional character; the only difference is that they do not appear in the display.
No comments:
Post a Comment
Use at your own risk.